About Disk I/O and Memory mapped files
In this post, I am attempting to explain File I/O in a simple way. This post covers what happens behind the scenes when application calls read, write system calls, what are the different types of reads/writes and lastly using Virtual Memory mapping to perform memory mapped I/O over files.
Using read, write system calls
Though reading and writing from files appears as just open, read, write and close, there are lot of things happening behind the scenes. To explain this, I will create a small C program that opens a file and reads the data.
#include<stdio.h>
#include<stdlib.h>
int main(int argc, char** argv) {
FILE *fp = fopen("data.txt", "r");
if (fp != NULL) {
char* data = (char*)malloc(512);
fread(data, 1, 512, fp);
printf("%s", data);
}
}
The above code opens a file called data.txt, if it is successful, creates a 512 bytes buffer on heap and then reads first 512 bytes of the file into that heap area from where our program can access it. Now let’s understand what exactly happens when we call read. (I took this diagram from here, so the real credits of this diagram goes to O’reilly)
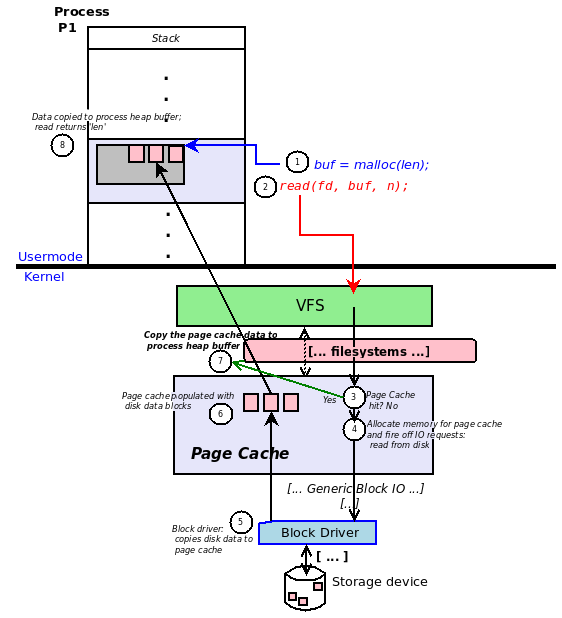
From the above diagram, we can see that read() system call propagates from the user application to the storage hardware. First, when a read() system call is made, the CPU switches to protected mode (the mode in which kernel runs) from user-mode and invokes the system call code. The kernel stores all the file descriptors currently opened in a list, that list is searched to obtain the inode information of the file descriptor, this inode contains all the low level details of a file specific to the device it is stored on. Once the inode information is obtained, the corresponding read() function associated with that inode is invoked. Since our file is a regular data file that resides on the disk, the read() function called on the inode internally invokes the Block I/O subsystem to read the data from underlying storage device.
The data from disk can be read in fixed block sizes. For example, older ATA disks support 512 bytes block size. SSDs on the other hand allow data to be read as fixed 4KB pages, all these things are abstract to the upper layers because the storage driver and Block I/O subsystem handles all these things. Block I/O subsystem calls the device driver code to read the contents and waits for the driver to complete the read. After read is complete, data is available to the Block I/O subsystem as blocks (or pages in SSD) of fixed sizes. For example, if we want to read 15KB of data, then the disk driver provides 4 pages (each of size 4KB). These pages are cached in a temporary in-memory buffer called Page Cache. Let’s understand what exactly the Page cache is used for.
Page cache
Calling the disk driver always to read data from the disk is not so performance friendly because the disk operation will touch lot of electronics other than CPU and memory, to avoid this problem, kernel stores recently used data blocks in a cache which resides on RAM (memory). Each page/block in this cache is identified by the block number. Block I/O subsystem checks this cache for the given block number/s before calling the disk driver, if the block/s is present, it is served directly from memory to avoid calling disk driver unnecessarily. If required blocks are not present in cache, they are read from the disk via disk driver then stored in the cache. In case of a write, the modifications are made directly on the data in cache (if present) and then marked as dirty, kernel periodically flushes the dirty blocks back to the disk, so they are persisted. Page cache behaves like LRU cache, so when size of the page cache is full, old blocks are removed to make room for latest blocks.
Irrespective of whether data is read from disk or from cache, in the end, Block I/O subsystem provides the required data to the upper layers. In other words, Block I/O subsystem returns the pointer to the entry of required data in page cache. This data is then copied to application’s buffer which was passed in during the read system call (in our case, the buffer was allocated on the application’s heap using malloc, we passed this buffer pointer as one of the parameters to fread function). This is how a read operation is performed at high level, the same thing applies to writes as well. Though we use many asynchronous operations like select, epoll aio etc, the underlying mechanism remains the same, the only difference is that the user application is allowed to execute other tasks and is notified back when the operation is complete by Block I/O subsystem.
Sequential and Random access
Sequential access involves reading/writing content from a file sequentially - i.e from start to some offset (Example: read first 0-563 bytes). Random access involves reading the contents at random positions - i.e at some arbitrary offsets (Example: read 67-90 bytes). File is always sequential, imagine it as a tape in tape-recorder and there is a metallic nail to go over it - i.e there is no way to access Nth byte of a file before starting from the beginning - this is same for both application and kernel, to access Nth byte we have to first seek to that position and then access it. But disk can either be sequential or random - that depends on the type of physical electronics we are using. For example HDD is sequential - we can do random access by moving the read/write head to a particular (sector, track, block) combination within a cylinder, however SSDs support Random Access for both reads and writes which is why SSDs are much faster than SSDs (we don’t have any mechanical seek like HDDs). Hardware data access is restricted from the user’s scope, because driver and drive firmware work together with hardware control unit to do that.
Caveats of using read and write system calls
In the approach we discussed in previous section we can clearly see some disadvantages:
- System call is made every time: Imagine we have 1GB of file and we allocate 32KB buffer on heap to read 32KB at a time then we have to make approximately 32768 read system calls. Even if we allocate 1 MB of buffer, we need to make 1024
readsystem calls. Imagine a database system that has 1000 queries per second, we have to make a system call for all the 1000 read requests (few queries may also involve multiple read calls) - this can be a performance bottleneck at large scale. - Lot of context switches: If we are using a thread pool for I/O, then everytime a thread requests for I/O, it will be preempted by another thread because the thread that requested for I/O blocks. If we are making thousands of such I/O requests every time, we have lot of context switches.
- Unnecessary read/writes and seeks during random access: As stated in previous section, files are sequential in nature, so reading/writing anything in between requires us to either seek manually to that location or read/wrute everything from the beginning. If we are making lot of random accesses, then we might have to seek lot of times. Since seek is also a system call, we are actually adding another unnecessary system call overhead.
- Redundant data copy: As stated in previous section, data is copied to/from page-cache/user-buffer everytime we make read/write system calls. This can be a bottleneck when we have large amounts of data to be read/written.
Memory mapped files
The concept of Virtual Memory is outside the scope of this blog, if you are a programmer probably you might have some idea about Paging and Memory management. Since Virtual memory uses mapped virtual addresses than directly using physical addresses, operating systems can map locations on disk to arbitrary locations in virtual address space and use this mapped region as if the contents are present on RAM. When the program tries to access such a virtual address which is not mapped to any physical memory location, a page fault is generated, upon page-fault, the kernel identifies where exactly the virtual address was mapped and then invokes the page fault handler that copies the required data from the disk. This feature allows user applications to map a file to some region in it’s own virtual address space and operating system will take care of providing the contents of the file while reading. Let us understand how exactly memory mapping of files work. Consider this C program, than opens the file and memory maps it, then tries to access the first 512 bytes.
#include <stdio.h>
#include <sys/mman.h>
#include <fcntl.h>
int main(int argc, char **argv) {
int fd = open("data.txt", 0);
// size of file 4KB is hardcoded for simplicity purpose.
const char* file_ptr = (const char*)mmap(NULL, 4096, PROT_READ, MAP_PRIVATE, fd, 0);
if (file_ptr != NULL) {
printf("%s\n", file_ptr);
}
}
The above program creates a memory mapping for file data.txt and reads the until it’s end. Under the hood, first kernel allocates a virtual memory region of 4KB starting from a random available virtual address. Though the memory region is mapped, the actual RAM is not yet consumed and data is not yet transferred from disk to the RAM for reading as this is only Virtual address mapping. mmap returns a pointer to the mapped memory region. We are using printf to print the data to the screen, this issues a memory access to the address pointed by the pointer, a page fault is generated because this memory region is not yet mapped to any physical RAM region. The kernel captures the page fault and uses then invokes a function that copies the data from the disk. For this, the kernel uses the same Block I/O subsystem as explained in the previous section. Block I/O subsystem copies the data to page cache and returns it’s address. The address of the data at page cache is then mapped to the virtual address that created a page-fault, thus the data is made available to the user application directly by mapping the page in page cache to the application’s virtual address space. As we saw, using mmap doesn’t require any system calls, everything is handled by the kernel using the page-fault trick.
Block Sizes and Memory mapping
Page sizes are fixed by the operating system, by default Linux uses 4KB pages, although we can enable 2MB and 1GB huge page sizes. Because of this fixed page sizes, the size of the block in page cache must be aligned with the page size, thus while using mmap we have to make sure that we deal with page size aligned data. Memory mapped files provide excellent support for random access, for example in the above code snippet if we assume the block-size (and page size) is 4KB then we can directly access the 10th block of the file just by adding an offset 10 * 4096 to the file_ptr (i.e file_ptr = file_ptr + (10 * 4096)), in this case the kernel automatically loads the 10th block of the file to the page cache and maps it to the virtual address file_ptr + (10 * 4096), i.e the 10th page of the memory mapped virtual address space.
mmap options
Here are some of the options that can be passed to mmap as per our application requirements:
- Protection Flags: The flags
PROT_EXEC,PROT_READ,PROT_WRITEcan be or-ed together to indicate the memory region created via mmap is executable, readable and writable, we can usePROT_NONEif we just want to create a mapping and not accessing it by any means (in my example above I have created the memory mapping in read-only mode by passingPROT_READ). - Visibility Flags: We can use
MAP_PRIVATEto make sure the mapped region is not available to other processes, in this case any updates made to the underlying data is copied to a separate page on RAM to make sure it stays private to the process that made the change.MAP_SHAREDwill make all the processes share the same underlying mapping, changes made to one process is visible to another.
If you are interested, you can read the man-page of mmap system call here.
Advantages of using mmap over read/write system calls
There are some advantages of using mmap instead of read and write.
- No system call is required: We don’t need to call
lseek,readandwritefor every read and write at random offsets, this reduces the system call overhead at scale. Thoughmmapcauses lot of page-faults, the overhead of page-faults is less when compared to system calls. - No redundant data copies: Page cache data is directly mapped to the application’s virtual address space, so data need not be copied from Page cache to application’s buffer. Thus
mmapcan be used for large data read/writes. - Sharing: We can use
MAP_SHAREDwithPROT_READ|PROT_WRITEto create a shared memory mapping over the same file where the writes from one process is immediately made visible to another process without any redundant copy or re-reading the same data.
Caveats of using memory mapped files
The flexibility of mmap comes with some caveats:
- I/O errors are fatal: When using
readandwritesystem calls, failures are properly propagated to the application via proper failure codes, but inmmapcase, any I/O error while accessing the mapped region can cause memory error in the kernel memory management sub-system and the application is exited immediately usingSIGBUSsignal. (we can handleSIGBUSexplicitly). - Synchronization issues: If the file is shared across two processes using
MAP_SHAREDandPROT_READ|PROT_WRITE, any of the process can write and read to the shared region without locks, thus locking system has to be implemented explicitly which is complex. - More memory overhead: When dealing with large files via
mmapwe are brining the majority of file to the memory by accessing contents at different offsets, this can bring lot of data to page cache and this can be a overhead for machines with less RAM.
Conclusion
This post was focused on two File I/O methods - i.e using read, write system calls and mmap. Both of these methods have their own advantages and caveats. No method is better than the other in general, the use of mmap or read/write system calls must be decided based on the use-case, type of data access pattern, size of files involved and volume of read/write operations.